Try the model on real ears
Click any otoscope image. These are held-out test images the model never trained on — including two it gets wrong.
Held-out test set · never seen in trainingInference runs the same PyTorch model exported from training.
What I learned about Blueberry
I started from the business, not the model. Here's the company I built this for.
Mission
Turn every family's living room into their own pediatric urgent care: home exam kits + 24/7 pediatricians + AI.
Built for Medicaid families — and it cuts ED costs by up to 50%.
The stack
Django + Hotwire (HTMX-like, server-rendered). The React Native app is being rewritten into Hotwire to simplify the stack. WebRTC lives inside their in-house EMR, on Google Cloud, with PyTorch / scikit-learn for ML.
Momentum
New leadership from MDLive (CEO) and Teladoc — the team is scaling, and engineering ownership is expanding with it.
What they value
- Start from the business problem, not the tech
- Impact over complexity
- Own work end-to-end — a "Manager of One"
- Human-in-the-loop, always
The four projects they're shipping — and how I'd build each
Matching the right tool to each problem matters more than reaching for ML every time.
Eardrum detection model
A transfer-learning CNN that triages otoscope images. Triage — not diagnosis.
Pretrained ResNet-18 backbone, class-weighted loss, doctor in the loop on every flag.
Developmental screeners
A scoring engine over validated questionnaires — ASQ-3, M-CHAT-R, CDC milestones — that flags delays for early intervention.
Deterministic scoring rules. Auditable, explainable, and exactly what clinicians already trust.
At-risk child flagging
A transparent rules engine on home-kit vitals first; then a calibrated XGBoost + SHAP model that prioritizes the physician queue.
Optimize for recall on the dangerous class — missing a sick child is the only error that truly costs.
WebRTC call reliability
TURN relay servers, ICE-restart on failure, adaptive bitrate, and getStats() metrics.
Families are often on weak connections — reliability is the product, not a nice-to-have.
How I built the eardrum model
A few hundred well-labeled ears, a pretrained backbone, and disciplined data hygiene.
Transfer learning on ResNet-18
The backbone already knows edges and textures, so a few hundred labeled ears are enough to specialize it. ResNet-18 is ~12M params — scaling accuracy is a data problem, not a compute one.
Trustworthy data only
The open Ohio / OtoMatch otoscope dataset: 454 expert-labeled images (Normal, Effusion, Tube), decoded from its labels spreadsheet into clean class folders. No web-scraped images — scraped labels are untrustworthy and unsafe for a medical model.
Handling imbalance & training
Class-weighted loss + augmentation to counter class imbalance. I also evaluated Zenodo, Figshare, and a Kaggle 956-image AOM set before settling on the cleanest source. The whole thing trains in ~2 minutes on an RTX 4060.
Results
98% overall on held-out data — and, crucially, the two misses were the safe kind.
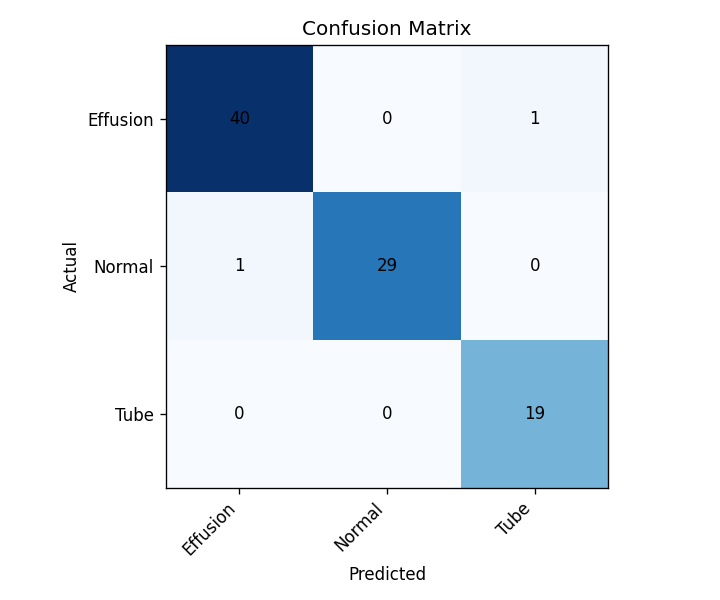
| Class | Precision | Recall |
|---|---|---|
| Effusion | 0.98 | 0.98 |
| Normal | 1.00 | 0.97 |
| Tube | 0.95 | 1.00 |
| Overall | 98% accuracy | |
Honest limitations & what's next
A prototype that hides its weaknesses isn't trustworthy. Here are mine.
Where it stops today
- Triage, not diagnosis — deliberately out of FDA device territory
- Random split, not patient-level — production must split by patient
- Only 3 classes, all from public data
- The real accuracy moat is Blueberry's own home-kit photos, labeled by its doctors
What I'd build next
- Active learning — label only images the model is unsure about
- An image-quality gate before inference
- Confidence calibration so scores mean what they say
- Expand to acute otitis media + earwax